7.图
图的基本概念;图的存储表示:邻接矩阵、邻接表
基本概念
详细见教材 7.1 节
存储表示
邻接矩阵
- 存储
1 | // 图的邻接矩阵存储表示 |
更适合存储稠密图,容易判定任意两个顶点是否有边连接
顶点度的计算
- 无向图:
\[ TD(v_i) = \sum^{n-1}_{j=0}{A[i][j]},n = MAX\_VERTEX\_NUM(即第 i 行元素之和) \]
- 有向图
\[ OD(v_i) = \sum^{n-1}_{j=0}{A[i][j]},n = MAX\_VERTEX\_NUM(即第 i 行元素之和) \]
\[ ID(v_j) = \sum_{i=0}^{n-1}A[i][j],n = MAX\_VERTEX\_NUM(即第 j 列元素之和) \]
- 对于网,对应度的大小,便是数对应位置的的非 \(\infty\) 的个数
邻接表
1 | // 图的邻接表存储表示 |
- 更适合存储稀疏图,容易寻找任意一个顶点的第一个邻接点和下一个邻接点。
- 顶点度的计算
- 无向图:顶点 \(v_i\) 的度为第 \(i\) 个链表中的结点数(头节点本身不算)
- 有向图:顶点 \(v_i\) 的出度为第 \(i\) 个链表中的结点数(头节点本身不算);入度则要遍历整个图
- 对于网,与上述方法对应相同
图的遍历与连通性
遍历
深度优先搜索
1 | // 下面两个算法用到的全局变量 |
1 | // 算法 7.4 |
1 | // 算法 7.5 |
- 性能分析
- 空间复杂度:\(O( |V| )\),其中$ |V|$ 为顶点数,下同
- 时间复杂度
- 邻接矩阵存储:\(O( |V|^2 )\)
- 邻接表存储:\(O(|V|+|E|)\) ,其中 \(|E|\) 为边数
广度优先搜索
1 | // 算法 7.6 |
- 性能分析(与 DFS 相同)
连通性
- 通过遍历,可以判断图的连通性
- 无向图
- 若连通,从任意一个顶点出发,只需一次遍历就能访问到途中所有顶点
- 若非连通,从某一顶点出发,一次遍历只能访问到该顶点所在连通分量的所有顶点
- 有向图
- 若初始点到图中所有顶点都有路径,则能够访问到图中所有的顶点;否则不能。
- 无向图
最小生成树
普里姆(Prim)算法
- 流程简述
- 初始化:向空树 \(T=(V_T,E_T)\) 中添加图 \(G=(V,E)\) 的任一顶点 \(u_0\) ,使 \(V_T = \{u_0\}\) , \(E_T=\varnothing\)
- 循环(重复下列操作至 \(V_T=V\)):从图 \(G\) 中选择满足 \(\{(u,v)|u\in V_T, v\in V-V_T\}\) 且具有最小权值的边 \((u,v)\) ,并置 \(V_T=V_T\cup \{v\}\) , \(E_T=E_T\cup \{(u,v)\}\)
1 | void Prim(G, T) |
- 性能分析
- 时间复杂度:\(O( |V| ^2)\)
- 适用于求解边稠密的图的最小生成树
克鲁斯卡尔(Kruskal)算法
- 流程简述
- 初始化: \(V_T = V \) , \(E_T=\varnothing\) 。即每个顶点构成一颗独立的树, \(T\) 此时是一个仅含 \(|V|\) 个顶点的森林
- 循环(重复下列操作至 \(T\) 是一棵树):按 \(G\) 的边权值递增的顺序依次从 \(E-E_T\) 中选择一条边,若这条边加入 \(T\) 后不构成回路,则将其加入 \(E_T\) ,否则舍弃,直到 \(E_T\) 中含有 \(n-1\) 条边
1 | void Kruskal(V, T) |
- 性能分析
- 时间复杂度:\(O(|E|log|E|)\)
- 适用于求解边稀疏而顶点较多的图的最小生成树
拓扑排序
- 流程简述
- 在有向图中选择一个没有前驱的顶点并输出
- 从图中删除该顶点和以它为尾的弧
- 重复以上两步,直至全部顶点均以输出
1 | Status TopologicalSort(ALGraph G) |
- 性能分析
- 时间复杂度:\(O(|V|+|E|)\)
关键路径
1 | Status TopologicalOrder(ALGraph G,SqStack *T) |
1 | Status CriticalPath(ALGraph G) |
- 性能分析
- 时间复杂度:\(O(|V|+|E|)\)
最短路径
迪杰斯特拉算法
1 | void ShortestPath_DIJ(MGraph G,int v0,PathMatrix *P,ShortPathTable *D) |
- 性能分析
- 时间复杂度:\(O(|V|^2)\)
### 弗洛伊德算法
1 | void ShortestPath_FLOYD(MGraph G,PathMatrix *P,DistancMatrix *D) |
- 性能分析
- 时间复杂度:\(O(|V|^3)\)
解题技巧小结及结论补充
图的应用相关算法手算流程小结
最小生成树
Prim 算法
- 集合定义
- \(V_T\) :最小生成树中间结果的点集(初始化,任取一点,或题设给出);
- \(V-V_T\) :还未归入最小生成树的点集
- 循环(直到 \(V_T = V\))
- \(V_T\) 中取一点 \(u\) , \(V-V_T\) 中取一点 \(v\) ,使得 \((u,v)\) 权值最小。
- 将 \(v\) 并入集合 \(V_T\)
Kruskal 算法
- 集合定义
- \(V_T\) :最小生成树的点集(初始化为 \(V\) ,即包含所有图中的点)
- \(E_T\) :存储最小生成树生成过程中边的集合(初始化为 \(\varnothing\))
- 循环(直至 \(T\) 是一棵树)
- 按 \(G\) 的边权值递增的顺序依次从 \(E-E_T\) 中选择一条边,若这条边加入 \(T\) 后不构成回路,则将其加入 \(E_T\) ,否则舍弃,直到 \(E_T\) 中含有 \(n-1\) 条边
最短路径
Dijkstra 算法
- 利用表格法求解
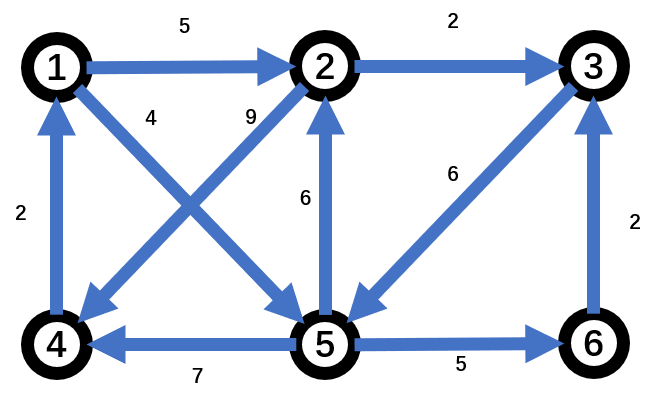
- 画下面的表格
- 起点直接能到达的结点在表格中的位置处填入,路径和对应长度。
- 不能直接到达的填正无穷。
- 将这一列的路径使得路径长度最短的结点(该路径此时的终点),并入集合 S 中(起点默认已经并入)
- 基于上一步得到的路径,看其终点有没有与其他点(这里的其他点 \(\in V-S\))之间相连。有的话,计算这个新的路径长度,并与上一个(对应行的左边一个)比较:若更小,则更新;否则照抄。
- 由此得到新的一列,继续比较路径大小。然后,选择最小的,将对应的结点并入 S 。
- 以此类推,得到以下表格:
| i=1 | i= 2 | i=3 | i=4 | i=5 | |
|---|---|---|---|---|---|
| 1(起点) | |||||
| 2 | (1,2)、5 | (1,2)、5(小) | |||
| 3 | \(\infty\) | \(\infty\) | (1,2,3)、7(小) | ||
| 4 | \(\infty\) | (1,5,4)、11 | (1,5,4)、11 | (1,5,4)、11 | (1,5,4)、11 |
| 5 | (1,5)、4(小) | ||||
| 6 | \(\infty\) | (1,5,6)、9 | (1,5,6)、9 | (1,5,6)、9(小) | |
| S | {1,5} | {1,5,2} | {1,5,2,3} | {1,5,2,3,6} | {1,5,2,3,6,4} |
Floyd 算法
- 初始化 \(dis^{(-1)}\) 为图的邻接矩阵
- 循环(邻接矩阵有 n 阶,外层就循环 n 次【从 0 到 n - 1】,主要是为了取将要加入以下路径点的点,设为 \(V_{intermediate}\))
- 内部再套两个循环(主要是为了取任意两个点的组合,设这两个点为
\[ V_{source}和V_{end} \]
)比较 \[ (1)\ Weight(V_{source},V_{intermediate})+Weight(V_{intermediate}, V_{end}) \]
和 \[ (2)\ Weight(V_{source},V_{end}) \] 大小,若(1)式更小,则更新对应 \(dis^{i}\) (i 代表循环变量【从 0 开始】)的
\(V_{source}\)所在行,
\(V_{end}\)所在列处的值
为 (1)式子的结果。
拓扑排序
- 较简单,具体见上
关键路径
- 几个时间的计算
- 顶点相关
- 事件 \(v_k\) 最早发生的时间 \(v_e(k)\)
- 从前往后算,计算从源点到当前点最长的路径长度。
- 入度>1 要注意,要取和最大
- 事件 \(v_k\) 最迟发生的时间\(v_l(k)\)
- 从后往前算(通常是后一个结点的最迟时间,减去这两点之间的权值)
- 出度>1 要注意,要取差最小
- 事件 \(v_k\) 最早发生的时间 \(v_e(k)\)
- 弧相关
- 活动 \(a_i\) 最早开始时间 \(e(i)\)
- 设 \(a_i\) 夹在两个顶点 \(v_k,v_j\) 之间,且 \(v_k\) 在前,则\(e(i) = v_e(k)\) (即前一个顶点最早发生时间)
- 活动 \(a_i\) 最迟开始时间 \(l(i)\)
- 设 \(a_i\) 夹在两个顶点 \(v_k,v_j\) 之间,且 \(v_k\) 在前,则\(l(i) = v_l(k)-Weight(v_k,v_j)\) (即后一个顶点最迟发生时间【减去】两点之间的权值)
- 活动 \(a_i\) 最早开始时间 \(e(i)\)
- 顶点相关
图的重要概念辨析及相关重要结论
重要概念辨析
无向完全图 VS 有向完全图
- 无向完全图:任意两个顶点都存在边
- 有向完全图:任意两个顶点都存在相反的两条弧
强连通图 VS 连通图
- 强连通图:(针对有向图)任意一对顶点都是强连通的(若从顶点 v 到 w 和 w 到v 都有路径,则这两个顶点是强连通的)
- 连通图:(针对无向图)任意两个顶点都是连通的(若从顶点 v 到 w 有路径,则这两个顶点是连通的)
强连通分量 VS 连通分量
- 强连通分量:(针对有向图)即为有向图中的极大强连通子图
- 连通分量:(针对无向图)即为无向图中的极大连通子图
重要结论
- 非连通图的判定:\(|V| = n\ 且\ |E| <n-1\)
- 无向图顶点的度:
\[ \sum^{n}_{i=1}TD(v_{i})=2|E| \]
- 有向图顶点的度:
\[ \sum^{n}_{i=1}ID(v_{i})=\sum^{n}_{i=1}OD(v_{i})= |E| \]
- 边数最少:对于连通无向图,即构成一棵树;对于强连通有向图,即构成一个有向环
- 一些极端情况可以考虑完全图、环等作为排除选项的反例。
- 图与树遍历关系
- 广度优先搜索相当于二叉树中的层序遍历
- 深度优先搜索相当于树中的先序遍历
- 广度优先搜索可用于解决无权(或等权)单源最短路径问题
- 遍历唯一性
- 邻接矩阵存储:唯一
- 邻接表存储:不唯一
- 有向图中的回路判定方法
- 拓扑排序
- 深度优先搜索:如果遍历过程中,将要访问的结点已在栈中,则有回路。
- DFS入栈顺序拓扑有序
- 一个连通图的生成树是图的极小连通子图
- 最小生成树的性质
- 一般形状不唯一(当图中各边权值互不相等,最小生成树唯一)
- 权值和唯一
- (★★★)边数 = 顶点数 - 1
- 单源最短路径,使用 Dijkstra ;每对顶点的的最短路径,使用 Floyd
- Dijkstra 不适用于带负权值;Floyd 不适用于包含带负权值的边组成回路
- n 个顶点、e 条弧有向图采用邻接表存储,拓扑排序时间复杂度O(n+e)(排序过程中,先找入度为 0 的点,再删除,非嵌套!另一角度,拓扑排序即是最终删除所有顶点和边,有 n 个顶点,e 条边,故总时间复杂度为 O(n+e))
- 若一有向图不能排成一个拓扑序列,则该图有环
- 要缩短工期,则所有关键路径上的点(每个关键路径上至少挑选一个进行时间压缩)都要同时减少(步骤:①找关键结点,得到其路径长度【设为 L】;②找所有路径长度为 L 的路径;③找到几个点,他们能覆盖到所有关键路径)
- 若用邻接矩阵存储有向图,矩阵中主对角线以下的元素均为 0 。则该图的拓扑排序存在,但不唯一( 2012 统考)
参考资料
- 数据结构(C语言版).严蔚敏等
- 2020年数据结构考研复习指导.王道论坛